I posted a version of this issue on LinkedIn. It struck a nerve. So I'm sharing a new version of it here with some additional thoughts for y'all. Specifically around the central question of... well, what do creators do?
* * *
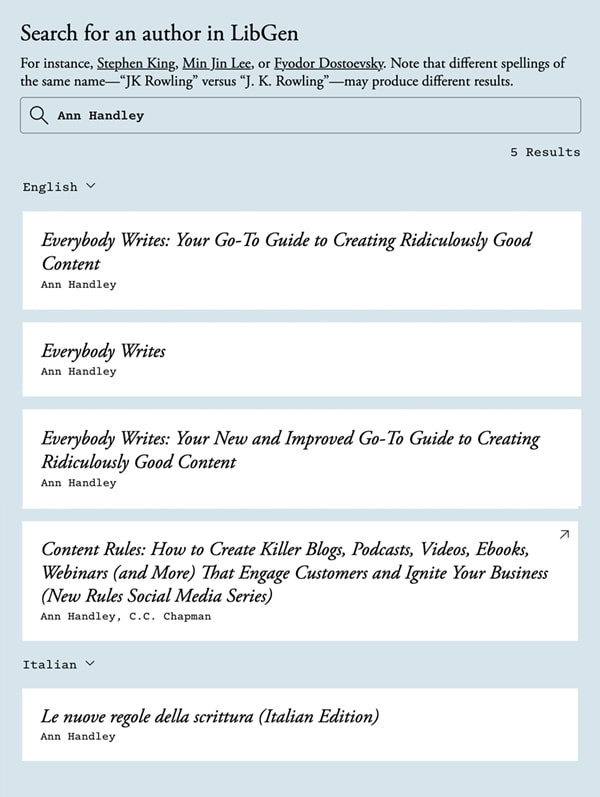
Meta used all 3 of my books & millions of other books, ebooks, and research papers to train its AI.
All without consent, compensation, copyright concern, credit. You find
out only by searching a database published a few days ago by The Atlantic.
It's sketchy AF. I'll tell you why in a sec. But first... should we care?
If you're on the list, you have one of these two reactions:
🥳 Honored! Flattered! My work is worthy!
😳 Ummm WTH. What about consent, compensation, etc.?
And what about non-authors?
🤔 Should anyone care whether Meta used 72 books from David Sedaris? 200 from Margaret Atwood? 19 from Alexander Chee? The entire library of everyone everywhere?
What's missing in this conversation is that Meta intentionally made ***A Choice***... as the kids say. They actively chose to steal the books, instead of going through the proper and legal channels, because the legal way was too slow.
TOO SLOW.
That's problematic, isn't it?
Meta years ago disavowed its famous Move Fast and Break Things motto. But that distancing
was cosplay—they pretended to be what they are not under heavy makeup and a mask. Now they are right back at it.
I use AI. I see its value. I am not Anti-AI by any stretch.
But the scale of this is nuts. And the behavior is... gross.
But I'm getting ahead of the story...
* * *
If Meta's Llama 3 was to compete with the likes of ChatGPT, it needed to be trained on a huge amount of
high-quality writing—books, not Instagram captions or LinkedIn posts or what have you. Acquiring all of that text legally could take time.
"Yo ho ho! Should we pirate it instead?" they wondered.
"Abso-tooting-lootly," they said back to themselves. "Let's loot all the books!"
Meta felt it was "really important to get books ASAP," since "books are actually more important than web data," The Atlantic said.
Books are important. This last line is the only line in this entire fiasco I actually agree with, but in a broken-clocks-are-right-twice-a-day way.
* * *
Enter LibGen, a pirate library with more than 7.5 million books and 81 million research papers. The Llama 3 team looted and rolled around in all the words like they were pirates rolling in gold doubloons. And they basically were.
So is it problematic? Yes. Here's why:
🏴☠️ We're normalizing the theft of IP to an absurd degree. A giant tech company should not feel entitled to scoop up all our words like they're in a bulk bin at a Dollar Tree & run straight out of the door with them.
🏴☠️ Gen AI often presents like all-knowing oracles, severed from sources. This "decontextualizes knowledge" (The Atlantic's phrase). This uncouples the work from the author. It prevents true collaboration. It makes it harder for creators and researchers to build an acknowledged body of work.
🏴☠️ Writing is not colorless, odorless "data." It's words that make up sentences that make up paragraphs that make up pages that writers have created, crafted, coaxed into the world. Words with handprints, heart-prints,
bitemarks, scratches from us trying to shape them into something that delights you.
Do I sound like I'm being precious about words? About writing? It's because I am.
* * *
So what's the alternative though?
Meta and other US tech companies say they need to stay competitive. From the perspective of an AI company, it is an arms race. Or a race for doubloons.
What about China! What about foreign
competition! Are the bad choices justified?
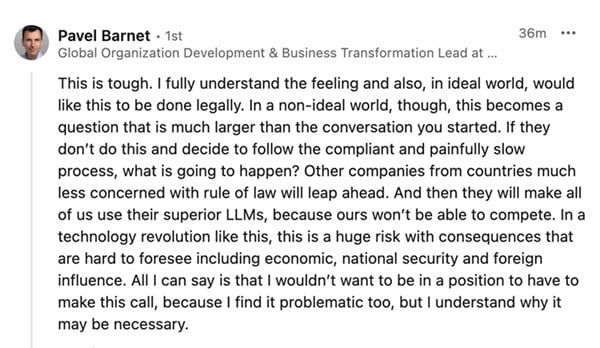
Pavel has a point here, one I've heard echoed from others: